|
AccFFT
|
#include <mpi.h>#include <omp.h>#include <iostream>#include <cmath>#include <math.h>#include <string.h>#include <cuda_runtime_api.h>#include <accfft_gpuf.h>#include <../src/operators_gpu.txx>Functions | |
| void | accfft_grad_gpuf (float *A_x, float *A_y, float *A_z, float *A, accfft_plan_gpuf *plan, std::bitset< 3 > *pXYZ, double *timer) |
| void | accfft_laplace_gpuf (float *LA, float *A, accfft_plan_gpuf *plan, double *timer) |
| void | accfft_divergence_gpuf (float *divA, float *A_x, float *A_y, float *A_z, accfft_plan_gpuf *plan, double *timer) |
| void | accfft_biharmonic_gpuf (float *BA, float *A, accfft_plan_gpuf *plan, double *timer) |
CPU functions of AccFFT operators
| void accfft_biharmonic_gpuf | ( | float * | BA, |
| float * | A, | ||
| accfft_plan_gpuf * | plan, | ||
| double * | timer | ||
| ) |
Computes single precision Biharmonic of its input real data A, and writes the output into BA. All the arrays must reside in the device (i.e. GPU) and must have been allocated with proper size using cudaMalloc.
| BA | 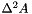 |
| plan | FFT plan created by accfft_plan_dft_3d_r2c_gpuf. Must be an outplace plan, otherwise the function will return without computing the gradient. |
| timer | See Timing AccFFT for more details. |
| void accfft_divergence_gpuf | ( | float * | divA, |
| float * | A_x, | ||
| float * | A_y, | ||
| float * | A_z, | ||
| accfft_plan_gpuf * | plan, | ||
| double * | timer | ||
| ) |
Computes single precision divergence of its input vector data A_x, A_y, and A_x. The output data is written to divA. All the arrays must reside in the device (i.e. GPU) and must have been allocated with proper size using cudaMalloc.
| divA | 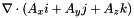 |
| A_x | The x component of 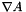 |
| A_y | The y component of |
| A_z | The z component of |
| plan | FFT plan created by accfft_plan_dft_3d_r2c_gpuf. Must be an outplace plan, otherwise the function will return without computing the gradient. |
| timer | See Timing AccFFT for more details. |
| void accfft_grad_gpuf | ( | float * | A_x, |
| float * | A_y, | ||
| float * | A_z, | ||
| float * | A, | ||
| accfft_plan_gpuf * | plan, | ||
| std::bitset< 3 > * | pXYZ, | ||
| double * | timer | ||
| ) |
Computes single precision gradient of its input real data A, and returns the x, y, and z components and writes the output into A_x, A_y, and A_z respectively. All the arrays must reside in the device (i.e. GPU) and must have been allocated with proper size using cudaMalloc.
| A_x | The x component of |
| A_y | The y component of |
| A_z | The z component of |
| plan | FFT plan created by accfft_plan_dft_3d_r2c_gpuf. Must be an outplace plan, otherwise the function will return without computing the gradient. |
| pXYZ | a bit set pointer field of size 3 that determines which gradient components are needed. If XYZ={111} then all the components are computed and if XYZ={100}, then only the x component is computed. This can save the user some time, when just one or two of the gradient components are needed. |
| timer | See Timing AccFFT for more details. |
| void accfft_laplace_gpuf | ( | float * | LA, |
| float * | A, | ||
| accfft_plan_gpuf * | plan, | ||
| double * | timer | ||
| ) |
Computes single precision Laplacian of its input real data A, and writes the output into LA. All the arrays must reside in the device (i.e. GPU) and must have been allocated with proper size using cudaMalloc.
| LA | 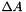 |
| plan | FFT plan created by accfft_plan_dft_3d_r2c_gpuf. Must be an outplace plan, otherwise the function will return without computing the gradient. |
| timer | See Timing AccFFT for more details. |
 1.8.9.1
1.8.9.1

